
En la primera parte de este artículo, exploramos qué es el Reinforcement Learning y vimos algunas de sus aplicaciones más destacadas. Ahora, es momento de sumergirnos en los detalles técnicos que hacen posible el RL.
Analizaremos los componentes esenciales del RL, incluyendo el agente, el entorno, el estado, la acción y la recompensa. Además, discutiremos los procesos de decisión de Markov, la importancia del equilibrio entre exploración y explotación, y los diferentes tipos de algoritmos de RL.
Esta comprensión técnica es fundamental para apreciar el verdadero potencial del RL y cómo puede aplicarse de manera efectiva en el mundo real.
Los 5 componentes fundamentales del RL
Para profundizar en los detalles sobre cómo funciona el RL, comenzaremos definiendo sus 5 componentes clave:
– Agente: El algoritmo o modelo que toma las decisiones.
– Entorno: Todo aquello con lo que interactúa el agente.
– Estado: La situación en la que se encuentra el agente en un momento dado.
– Acción: Cada una de las posibles decisiones que el agente puede tomar.
– Recompensa: El valor positivo o negativo obtenido por realizar cierta acción.
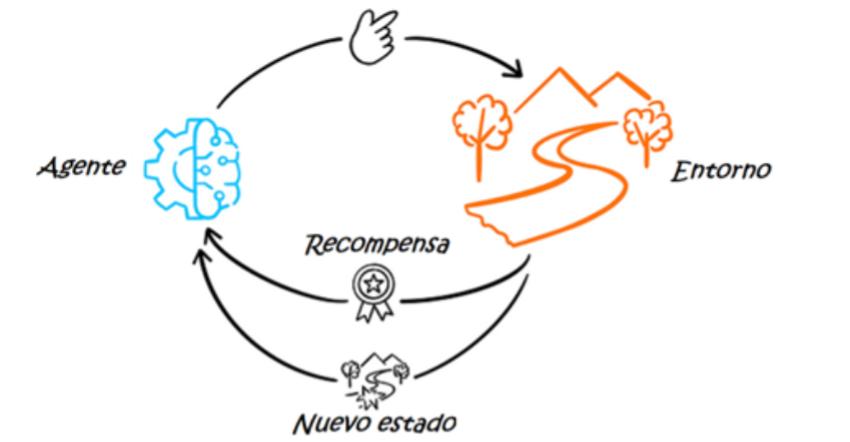
Procesos de decisión de Markov
El Reinforcement Learning se basa en los principios del proceso de decisión de Markov, un modelo matemático para la toma de decisiones en intervalos discretos de tiempo. En este proceso, el agente realiza una acción en cada paso temporal, lo que da lugar a un nuevo estado del entorno. El estado actual del entorno está determinado por la secuencia de las acciones pasadas realizadas.
Conforme el agente interactúa con el entorno mediante prueba y error, genera un conjunto de políticas o reglas. Básicamente, la política es la estrategia que emplea el agente para determinar, dado un estado del entorno, qué acción realizar para maximizar las recompensas.

Visualicémoslo mejor con un ejemplo. Consideremos un robot aspirador autónomo, que utiliza el Reinforcement Learning para limpiar una casa de manera eficiente. Cada acción que realiza el robot (moverse o aspirar) cambia el estado del entorno (la distribución de las áreas limpias y la posición actual del robot) y proporciona una recompensa: positiva por limpiar correctamente una zona o negativa si choca con un obstáculo o vuelve a limpiar una zona ya limpia, desperdiciando batería y tiempo.
Con el tiempo, el robot aprende una política óptima para maximizar su eficiencia en la limpieza, es decir, cómo moverse y aspirar para limpiar la casa completa de la manera más efectiva posible.
Equilibrio entre exploración y explotación
Otro concepto clave en el RL es el equilibrio entre exploración y explotación. Imagina que quieres ir a cenar a un restaurante esta noche. Puedes ir a tu sitio favorito como haces casi siempre (esto sería explotación), o bien puedes probar un restaurante nuevo del que te han hablado muy bien pero nunca has visitado (exploración). Puede que el nuevo restaurante te guste más, o puede que no, pero si no vas, nunca lo sabrás.

Ahora, imagina que haces esto durante un año. Al principio, es probable que quieras explorar muchos restaurantes nuevos para descubrir cuál es el mejor. Con el tiempo, conforme vas descubriendo cuáles te gustan más, empezarás a explotarlos y a visitarlos con más frecuencia. Sin embargo, de vez en cuando, seguirás probando lugares nuevos para asegurarte de que no te estás perdiendo algo mejor.
En el caso del Reinforcement Learning, ocurre lo mismo. La exploración se refiere a encontrar nuevas políticas y puede dar lugar al descubrimiento de estrategias y acciones que ofrezcan mejores recompensas que las ya conocidas, pero también puede ser ineficiente a corto plazo al elegir acciones que quizá den recompensas menores. Por otro lado, la explotación implica usar estrategias exitosas ya conocidas y puede ser muy eficiente a corto plazo al elegir siempre la acción conocida que maximiza las recompensas, pero podría evitar que el agente descubra otras estrategias potencialmente mejores, provocando así un peor rendimiento y menores recompensas a largo plazo. Por ello, es crucial encontrar un equilibrio entre ambas estrategias, siendo la exploración normalmente más intensiva al principio y disminuyendo con el tiempo a medida que se adquiere más conocimiento sobre el entorno.
Tipos de algoritmos de Reinforcement Learning
Aunque existen varios algoritmos que se usan en el Reinforcement Learning, todos ellos pueden agruparse en dos categorías: el RL basado en modelos y el RL sin modelo.
Reinforcement Learning sin modelo
Se utiliza generalmente en entornos estáticos y bien definidos, es decir, en escenarios que conocemos por completo y sabemos cómo reaccionan a cada acción.
Imagina un robot en un almacén desconocido que necesita encontrar un artículo específico. Al comenzar, el robot explora meticulosamente el almacén, construyendo un mapa detallado de su distribución interna y ubicaciones clave como estanterías y zonas de almacenamiento. Por ejemplo, podría identificar la ubicación de un artículo después de explorar un determinado número de pasillos. Con este mapa en mente, el robot planifica rutas eficientes para recuperar artículos de manera rápida y precisa en futuras misiones de recolección.

En definitiva, en un RL basado en modelos, el agente tiene acceso al modelo del entorno, conociendo las acciones necesarias para ir de un estado del entorno a otro, con sus probabilidades y recompensas correspondientes. Para crear dicho modelo, el agente realiza acciones en el entorno y observa el nuevo estado y el valor de la recompensa. Luego, asocia la transición de acción-estado con el valor de esa recompensa.
Reinforcement Learning sin modelo
Se utiliza en entornos grandes, dinámicos, complejos y que no son fáciles de caracterizar o definir. Al ser entornos cambiantes, el agente no puede crear un modelo que defina las acciones con sus correspondientes probabilidades y recompensas. En su lugar, estima la mejor estrategia directamente desde la experiencia, sin tener conocimiento sobre las recompensas que va a obtener.
Por ejemplo, los coches Tesla emplean Reinforcement Learning sin modelo para mejorar su sistema de conducción autónoma. Como ya explicamos en la primera parte de este artículo, el sistema aprende de una amplia gama de situaciones de tráfico real a partir de la recopilación de datos de millones de kilómetros conducidos por usuarios.
Inicialmente, se entrena en entornos simulados, donde el vehículo toma decisiones basadas en su estado actual y recibe recompensas o penalizaciones. Con el tiempo, al entrenarse en escenarios virtuales y reales, el vehículo desarrolla una política de comportamiento efectiva sin modelar explícitamente toda la dinámica del tráfico (patrones de tráfico, el comportamiento de los peatones, condiciones meteorológicas, etc.), refinándola continuamente con nuevos datos del mundo real.
Diferencias entre aprendizaje supervisado, no supervisado y por refuerzo
El Reinforcement Learning es un método que se encuentra entre los dos métodos clásicos del aprendizaje automático o Machine Learning (ML): el aprendizaje supervisado y el no supervisado. Aunque los tres son métodos de aprendizaje pertenecientes al ámbito del Machine Learning, existen diferencias significativas entre ellos.
En el aprendizaje supervisado es necesario tener los datos etiquetados. Esto significa que los datos de entrada deben tener una salida definida, como en un conjunto de imágenes de gatos y perros donde cada imagen está etiquetada correctamente como «gato» o «perro». El objetivo de estos algoritmos es encontrar patrones y relaciones entre los conjuntos de datos de entrada y salida y, basándose en un conjunto de datos de entrada nuevo, predecir la salida.
Por otro lado, los algoritmos de aprendizaje no supervisado reciben un conjunto de datos como entrada, pero no tienen una salida específica definida. Estos algoritmos encuentran relaciones y patrones ocultos en los datos mediante métodos estadísticos, típicamente utilizando técnicas de clustering como K-means. Por ejemplo, en marketing, se pueden agrupar clientes por segmentos en función de sus comportamientos y sus compras sin tener etiquetas predefinidas.
Finalmente, el RL se encuentra en algún lugar intermedio entre estos dos tipos de aprendizaje.
El RL requiere la definición de un sistema de recompensas y penalizaciones para guiar el aprendizaje del agente. Las recompensas deben reflejar el éxito en la tarea, incentivando acciones beneficiosas, mientras que las penalizaciones deben desincentivar acciones perjudiciales.
Este sistema debe ser diseñado cuidadosamente para que el agente aprenda comportamientos deseados, y para ello es importante establecer un buen balance entre recompensas y penalizaciones para evitar que el agente desarrolle comportamientos subóptimos. El objetivo es que el modelo interactúe con el entorno y aprenda a tomar decisiones mediante prueba y error, dando mayor importancia a aquellas acciones que maximizan las recompensas.
Entonces, a diferencia del aprendizaje supervisado, donde se requieren datos etiquetados para entrenar el modelo, el RL tiene un objetivo final definido pero no depende de datos etiquetados. Por otro lado, en contraste con el aprendizaje no supervisado, que también prescinde de etiquetas pero se centra en descubrir patrones internos, el RL necesita un sistema bien definido de recompensas y penalizaciones.
¿Cuáles son los desafíos del Reinforcement Learning?
A pesar de su potencial, el Reinforcement Learning todavía enfrenta desafíos que lo separan de alcanzar el mismo impacto que tienen otras ramas del Machine Learning, como el aprendizaje supervisado y el no supervisado.
Uno de los retos principales del RL es la necesidad de proporcionar un entorno donde el agente pueda experimentar y aprender de manera segura. En este sentido, los sistemas basados en recompensas y castigos pueden ser limitantes en ciertos contextos. Por ejemplo, en la conducción autónoma, entrenar un modelo directamente en el mundo real podría conllevar riesgos de accidentes. Para evitar estos peligros, es esencial realizar el entrenamiento inicial en simuladores, aunque esto a su vez puede plantear limitaciones en términos de la fidelidad del entorno simulado con respecto al mundo real.
Además, aunque el modelo funcione bien en un entorno controlado, transferir luego ese conocimiento a un entorno real es muy complicado. Esto también conlleva a que el RL sea menos práctico.

Conclusiones
En esta segunda parte, hemos desglosado los componentes fundamentales del Reinforcement Learning y explicado cómo interactúan para permitir que un agente aprenda y tome decisiones óptimas en un entorno dado. Hemos explorado los procesos de decisión de Markov y la importante interacción entre exploración y explotación, así como los diferentes enfoques de RL basados en modelos y sin modelos. Estos conocimientos técnicos nos proporcionan una base sólida para entender cómo el RL puede ser implementado y mejorado.
Sin embargo, el RL aún enfrenta varios desafíos importantes, como la necesidad de entornos de entrenamiento seguros y realistas y la dificultad de transferir el conocimiento del entorno de entrenamiento al real. A medida que se superen estos obstáculos y se desarrollen nuevas técnicas, el RL seguirá expandiendo sus aplicaciones y su impacto en diversas industrias, consolidándose como una herramienta esencial en el ámbito del Machine Learning debido a su aplicabilidad y eficiencia.


