
In the first part of this article, we explored what Reinforcement Learning is and looked at some of its most prominent applications. Now, it’s time to dive into the technical details that make RL possible.
We will analyze the essential components of RL, including agent, environment, state, action, and reward. In addition, we will discuss Markov decision processes, the importance of the trade-off between exploration and exploitation, and the different types of RL algorithms.
This technical understanding is essential to appreciate the true potential of RL and how it can be effectively applied in the real world.
The 5 fundamental components of LR
To delve into the details of how the LR works, we will start by defining its 5 key components:
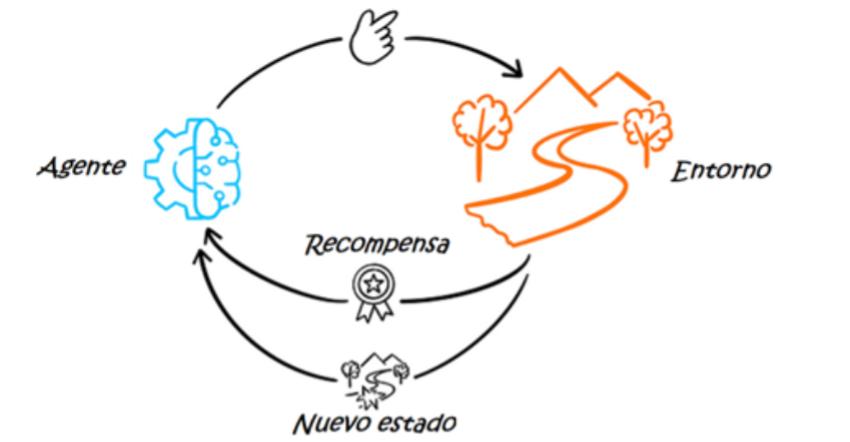
– Agent: The algorithm or model that makes the decisions.
– Environment: Everything with which the agent interacts.
– State: The situation in which the agent is at a given time.
– Action: Each of the possible decisions that the agent can take.
– Reward: The positive or negative value obtained for performing a certain action.
Markov decision processes
Reinforcement Learning is based on the principles of the Markov decision process, a mathematical model for decision making in discrete time intervals. In this process, the agent performs an action at each time step, resulting in a new state of the environment. The current state of the environment is determined by the sequence of past actions performed.
As the agent interacts with the environment through trial and error, it generates a set of policies or rules. Basically, the policy is the strategy used by the agent to determine, given a state of the environment, what action to take to maximize rewards.

Let’s visualize it better with an example. Let’s consider an autonomous vacuuming robot, which uses Reinforcement Learning to clean a house efficiently. Each action performed by the robot (moving or vacuuming) changes the state of the environment (the distribution of the cleaned areas and the robot’s current position) and provides a reward: positive for successfully cleaning an area or negative if it hits an obstacle or re-cleans an already cleaned area, wasting battery and time.
Over time, the robot learns an optimal policy to maximize its cleaning efficiency, i.e. how to move and vacuum to clean the entire house as effectively as possible.
Balance between exploration and exploitation
Another key concept in LR is the balance between exploration and exploitation. Imagine you want to go to a restaurant for dinner tonight. You can either go to your favorite place as you almost always do (this would be exploitation), or you can try a new restaurant that you have heard good things about but have never visited (exploration). You may like the new restaurant better, or you may not, but if you don’t go, you’ll never know.

Now, imagine doing this for a year. At first, you’ll probably want to explore a lot of new restaurants to find out which ones are the best. Over time, as you discover which ones you like best, you’ll start to exploit them and visit them more frequently. However, from time to time, you’ll keep trying new places to make sure you’re not missing out on something better.
The same applies to Reinforcement Learning.. Exploration refers to finding new policies and may lead to the discovery of strategies and actions that offer better rewards than those already known, but may also be inefficient in the short run by choosing actions that may yield lower rewards. On the other hand, exploitation involves using already known successful strategies and may be very efficient in the short run by always choosing the known action that maximizes rewards, but could prevent the agent from discovering other potentially better strategies, thus leading to worse performance and lower rewards in the long run. Therefore, it is crucial to find a balance between the two strategies, with exploration usually being more intensive at the beginning and decreasing over time as more knowledge about the environment is acquired.
Types of Reinforcement Learning algorithms
Although there are several algorithms used in Reinforcement Learning, all of them can be grouped into two categories: model-based RL and model-free RL.
Reinforcement Learning without model
It is generally used in static and well-defined environments, i.e. in scenarios that we are completely familiar with and know how they react to each action.
Imagine a robot in an unfamiliar warehouse that needs to find a specific item. As it begins, the robot meticulously scans the warehouse, building a detailed map of its internal layout and key locations such as shelves and storage areas. For example, it might identify the location of an item after scanning a certain number of aisles. With this map in mind, the robot plans efficient routes to retrieve items quickly and accurately on future picking missions.

In short, in a model-based RL, the agent has access to the model of the environment, knowing the actions needed to go from one state of the environment to another, with their corresponding probabilities and rewards. To create such a model, the agent performs actions in the environment and observes the new state and reward value. It then associates the action-state transition with the value of that reward.
Reinforcement Learning without model
It is used in large, dynamic, complex environments that are not easy to characterize or define. As these are changing environments, the agent cannot create a model that defines the actions with their corresponding probabilities and rewards. Instead, it estimates the best strategy directly from experience, without knowledge of the rewards it will obtain.
For example, Tesla cars use model-free Reinforcement Learning to improve their autonomous driving system. As we explained in the first part of this article, the system learns from a wide range of real-world traffic situations by collecting data from millions of miles driven by users.
Initially, it is trained in simulated environments, where the vehicle makes decisions based on its current state and receives rewards or penalties. Over time, by training in virtual and real scenarios, the vehicle develops an effective behavioral policy without explicitly modeling all traffic dynamics (traffic patterns, pedestrian behavior, weather conditions, etc.), continuously refining it with new real-world data.
Differences between supervised, unsupervised and reinforcement learning
Reinforcement Learning is a method that lies between the two classic Machine Learning (ML) methods: supervised and unsupervised learning. Although all three are learning methods belonging to the Machine Learning field, there are significant differences between them.
In supervised learning it is necessary to have labeled data. This means that the input data must have a defined output, as in a set of cat and dog images where each image is correctly labeled as “cat” or “dog”. The goal of these algorithms is to find patterns and relationships between the input and output data sets and, based on a fresh input data set, predict the output.
On the other hand, unsupervised learning algorithms receive a set of data as input, but do not have a specific defined output. These algorithms find hidden relationships and patterns in the data by statistical methods, typically using clustering techniques such as K-means. For example, in marketing, customers can be grouped by segments based on their behaviors and purchases without having predefined labels.
Finally, RL lies somewhere in between these two types of learning.
RL requires the definition of a system of rewards and penalties to guide the agent’s learning. Rewards should reflect success in the task, incentivizing beneficial actions, while penalties should discourage detrimental actions.
This system must be carefully designed so that the agent learns desired behaviors, and for this it is important to establish a good balance between rewards and penalties to prevent the agent from developing suboptimal behaviors. The objective is that the model interacts with the environment and learns to make decisions through trial and error, giving greater importance to those actions that maximize rewards.
So, unlike supervised learning, where labeled data are required to train the model, RL has a defined end goal but does not rely on labeled data. On the other hand, in contrast to unsupervised learning, which also dispenses with labels but focuses on discovering internal patterns, RL needs a well-defined system of rewards and penalties.
What are the challenges of Reinforcement Learning?
Despite its potential, Reinforcement Learning still faces challenges that separate it from achieving the same impact as other branches of Machine Learning, such as supervised and unsupervised learning.
One of the main challenges of RL is the need to provide an environment where the agent can safely experiment and learn. In this regard, reward- and punishment-based systems can be limiting in certain contexts. For example, in autonomous driving, training a model directly in the real world could lead to risks of accidents. To avoid these dangers, it is essential to perform the initial training on simulators, although this in turn may pose limitations in terms of the fidelity of the simulated environment with respect to the real world.
Moreover, even if the model works well in a controlled environment, transferring this knowledge to a real environment is very complicated. This also makes the RL less practical.

Conclusions
In this second part, we have broken down the fundamental components of Reinforcement Learning and explained how they interact to enable an agent to learn and make optimal decisions in a given environment. We have explored Markov decision processes and the important interplay between exploration and exploitation, as well as the different model-based and model-free approaches to RL. This expertise provides us with a solid foundation for understanding how RL can be implemented and improved.
However, RL still faces several important challenges, such as the need for safe and realistic training environments and the difficulty of transferring knowledge from the training environment to the real one. As these obstacles are overcome and new techniques are developed, RL will continue to expand its applications and impact in various industries, consolidating itself as an essential tool in the Machine Learning field due to its applicability and efficiency.


