Defect prediction: what are we talking about?
Let’s imagine a factory in which the machines work perfectly with optimum efficiency and do not generate any type of defect in the manufactured products. This would be an ideal scenario, but the reality is that this does not happen, because machines fail, misalignments occur in different parameters that affect the production process, and the quality of some parts is affected.
Today, according to the ASQ(American Society for Quality), the costs related to quality control within industries account for between 15% and 40% of the revenues.
This is because these processes are mainly based on the detection of defects a posteriori, i.e., once the part has been produced. It is then that the part is checked and either discarded or the defect is corrected, with all the costs that this entails both economically and in terms of production time.
In this context, preventive detection carried out with Artificial Intelligence (AI) techniques can be a great solution. In this article, we will explain the different alternatives that exist when offering an AI solution, related to predictive analytics, for the prediction of quality defects, and we will give some tips to be able to address this kind of challenges.
But what is predictive analytics? Predictive analytics is defined as the application of mathematical models to identify the probability of future events based on historical data. The main objective is to understand what has happened to provide the best assessment of what will happen in the future.
For our case, we want to predict whether a part is going to present some kind of defect or not from different manufacturing parameters. There are different techniques for this, such as classification models or neural networks, which are useful in providing these predictions.
In this article we are going to focus on two of the most popular techniques to address this type of challenges: Supervised Machine Learning with classification models and Deep Learning with neural networks.
Defect prediction with classification models
Classification models are algorithms designed to predict the class to which a data set belongs, based on characteristics known as predictor variables. These classes can be binary (e.g. there is defect or no defect) or multiple (e.g. different types of defects). In order to achieve this prediction on new data, classification models use historical data to learn patterns, and then apply that knowledge on new data.
The popularity of these algorithms lies mainly in their efficiency in data processing, which implies a high capacity for handling large volumes of data, and their ability to adapt to different situations. In addition, these models are relatively easy to understand and interpret, which allows us to identify the characteristics or variables that most influence the prediction in a simple way.
The most commonly used algorithms are Random Forest and XGBoost, both based on sets of decision trees. To get an idea, these decision trees are like a decision flow where each question narrows down the options, until a conclusion is reached, just like in the “Who’s Who?” game.
Let’s see briefly what these algorithms consist of, their advantages and limitations.
Random Forest:
In this model, each tree is constructed independently using a random sample of the data and only a portion of the features. Then, the predictions from each tree are combined to determine the final class.
PROS – This type of training can be parallelized, which makes it more efficient when dealing with large data sets.
CONS – It does not work well when we have unbalanced data, unless we previously apply balancing techniques.
XGBoost (Extreme Gradient Boosting):
Instead of building trees independently, XGBoost iteratively improves an existing model to minimize prediction error. Each tree is built sequentially, and subsequent trees focus on correcting errors made by previous trees using gradient boosting techniques.
PROS – An important feature of XGBoost is that it allows greater hyperparameter tunability, which can lead to better performance. It is also capable of handling missing values without the need for imputation.
CONS – XGBoost is less robust with noisy data. Also, that many hyperparameters means more complexity in configuration.
The difference in the construction and combination of the decision trees between the two models means that both their sensitivity to overfitting and the complexity of hyperparameter adjustment are very different. The choice between one or the other depends mainly on the specific data set of the problem at hand.
Both constructions can be seen visually in the following graph:
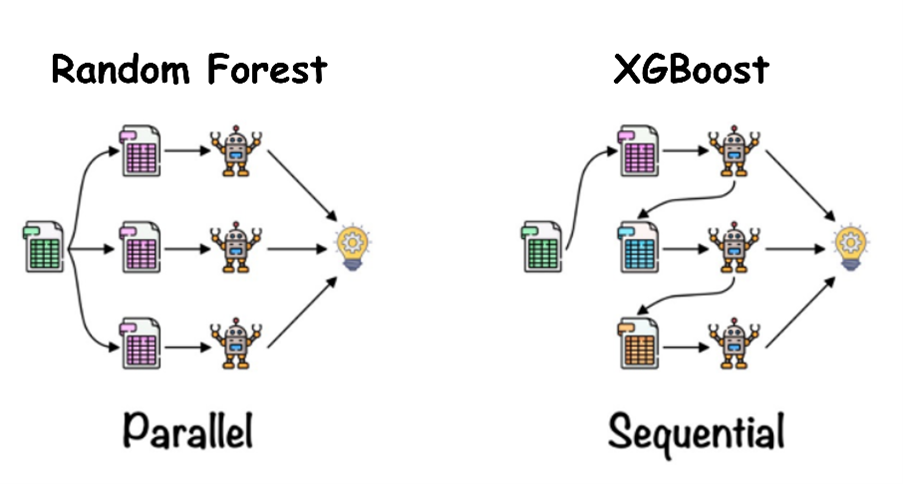
Credits: https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/
Both Random Forest and XGBoost are more “traditional” models as far as classification problems are concerned. As the main novelty within AI we have neural networks.
Defect prediction with neural networks
These computational models process data in a manner inspired by the way the human brain does. To do so, they use interconnected nodes in a layered structure, creating an adaptive system that learns from its mistakes and continuously improves.
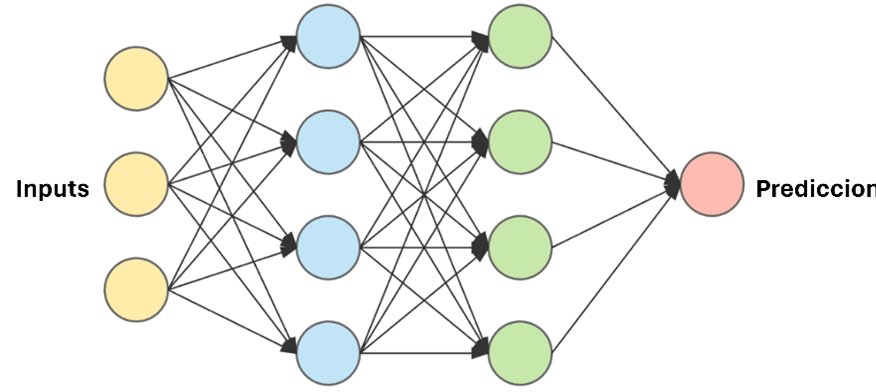
Credits: https://openwebinars.net/blog/que-son-las-redes-neuronales-y-sus-aplicaciones/
For quality defect prediction, we have different types of neural network architectures.
The simplest is the perceptron, consisting of a single neuron that is capable of binary classification. From it, networks with more layers composed of these perceptrons can be built, which increases the complexity of the algorithm.
There are also much more complex networks such as CNNs (Convolutional Neural Networks). This type of architecture is used when the problem requires identifying defects from images of the part.
PROS – These algorithms have a high learning capacity and are very flexible, since they can be designed in a thousand ways.
CONS – They are models that need a large amount of data to train, use a high number of hyperparameters and have a very high computational cost. This means that, although they are very novel methods, using them in some simple classification problems would be, as the expression goes, “killing flies with cannons”.
So: how to choose?
So, knowing how these algorithms work, how do we know which one to choose? Which one is more advisable for our case?
In different projects we have had in PredictLand AI, related to the prediction of quality defects in automotive companies, we have chosen to use classical classification models such as Random Forest and XGBoost. They gave excellent results for this particular problem and are easy to interpret by the customer.
Main challenge: data
Recall that these classification models are responsible for looking for patterns in the data. Therefore, it is important not only to have a good data history, but also to have good quality data.
But how can we determine that data quality? This is where descriptive analytics and customer communication come into play. This communication is key to understanding the business objectives in order to understand the data and then clean it and build useful information for our model.
When we talk about quality defect prediction within a manufacturing process, one of the things that one usually comes across is different tables that refer to different machines in the process. In order to be able to cross all these tables and get a single table that collects all the data, it is important that throughout the process the part on which the defect is to be determined is well identified.
It should also be taken into account that the different machines in the process can have a large number of parameters that can act as predictor variables for our model. This data analysis can help us to have a first approximation of which variables may be important, as well as what form they have and the possible transformations needed to apply one model or another.
5 steps in a real case
The question we must ask ourselves now is, can I use this type of techniques for my case?
To answer this question, let’s look at the key points for approaching a quality defect prediction project based on our experience:
- Gather as much data as possible. This helps to have a good history of the different parameters that are in the machine of the manufacturing process in question.
- Add external data, if possible, that may affect the manufacturing process such as ambient temperature or humidity.
- Analyze the data to familiarize yourself with it and determine which variables are important in the manufacturing process. At this point it is useful to communicate with the customer so that they can contribute their knowledge and intuition about the process.
- Select several models and test them by measuring different metrics.
- It chooses the model that best suits the problem and provides the best results and decides, together with the customer, the number of parts on which a defect alarm is to be given.
By following these tips, significant cost and time savings can be achieved in the manufacturing process, thus improving operational efficiency. For example, a company that produces 1000 parts per day and has to check 400 of these parts can benefit from using a model that detects 80% of the defects within 20% of the manufactured parts (which would be 200 parts). This optimizes the time of the quality review staff.
Conclusion
In summary, the high costs associated with quality controls in industries are largely attributed to ex-post defect detection processes. The introduction of AI techniques such as supervised Machine Learning with classification models can help us to solve the early detection of quality defects in our production process.
However, the success of these models is highly dependent on the quality and availability of the data. Therefore, it is essential to perform data analysis and collaborate with the customer to understand the business objectives and select the relevant variables for the manufacturing process.
Finally, by following the above tips, we may be able to successfully implement AI solutions in the prediction of these quality defects. This way we achieve significant savings in both cost and time.


